Flock meets OpenClaw: Enterprise-Ready Agentic AI with First-Class Agent Integration
Contents
- The AI That Does Things, Now with Enterprise Orchestration
- What’s New in Flock v0.5.400
- Architecture: Engine-Level Integration
- Getting Started
- What You Can Build
- Error Handling
- Running Agentic AI in a Secured Environment
Flock’s declarative type contracts and blackboard architecture bring enterprise-grade orchestration to OpenClaw’s powerful AI agents. Engine-level integration preserves full blackboard semantics with zero feature compromise.
The AI That Does Things, Now with Enterprise Orchestration
Flock is a production-focused framework for orchestrating AI agents through declarative type contracts and blackboard architecture. These are proven patterns from distributed systems, decades of microservice experience, and classical AI, now applied to modern LLMs. With typed artifacts, reactive subscriptions, zero-trust visibility controls, and real-time observability, Flock provides the foundation for agentic AI that enterprises can trust, observe, and audit.
OpenClaw is the AI that actually does things. It clears your inbox, sends emails, manages your calendar, checks you in for flights. All from WhatsApp, Telegram, or any chat app you already use. Created by Peter Steinberger, OpenClaw has become one of the fastest-growing open-source projects in GitHub history, with over 220000 stars, because it proved what users want: AI agents that act, not just answer. No IDE, no terminal, no developer background required.

But OpenClaw has a blind spot: it doesn’t orchestrate.
When you need multiple OpenClaw agents to collaborate (passing structured data between them, routing work based on intermediate results, running tasks in parallel and joining the outputs, enforcing security boundaries between agents) you’re on your own. OpenClaw’s multi-agent model is spawn-and-wait. There’s no typed data flow, no conditional routing, no fan-out/fan-in, no shared workspace, and no pipeline-level observability. Sub-agents can’t even notify siblings directly.
Flock fills every one of those gaps. Its blackboard architecture was designed for exactly this: coordinating autonomous agents through typed artifacts, reactive subscriptions, visibility controls, and declarative workflow conditions. The combination gives you OpenClaw’s execution power with Flock’s orchestration intelligence. Autonomous agents that don’t just act, but act together.
With this integration, Flock brings these two worlds together. OpenClaw’s natural-language accessibility and rich toolkit (tools, skills, web search, file access, multi-step reasoning) now operate within Flock’s typed, observable, governed pipelines. The product manager delegating research via WhatsApp. The sales rep whose agent maintains CRM entries after every call. The team lead automating logistics through Telegram. All of it orchestrated with the same declarative contracts, visibility boundaries, and production safety nets that platform teams rely on.
Personal AI productivity, scaled to enterprise workflows.
What’s New in Flock v0.5.400
Flock v0.5.400 introduces openclaw_agent(), a new builder method that enables OpenClaw gateway agents to participate as first-class members of Flock pipelines. OpenClaw agents, with their access to tools, skills, web search, file systems, and multi-step reasoning, can now produce typed artifacts that flow through Flock’s blackboard alongside outputs from native LLM agents.
The integration is designed around Flock’s existing engine architecture, ensuring that all orchestration features (subscriptions, visibility controls, fan-out publishing, workflow conditions, tracing, and dashboard visualization) work without modification.
Architecture: Engine-Level Integration
OpenClaw is implemented as an Engine within Flock’s component model. This is a deliberate architectural choice: engines handle the „how to compute output“ concern while leaving all orchestration semantics untouched.
An OpenClaw agent is a standard Flock agent with a different compute backend. The orchestrator, blackboard, subscription engine, visibility layer, and dashboard are unaware of the difference. This ensures complete feature parity without special-casing.
The OpenClawEngine handles five steps per invocation:
- Serialize input artifact and output Pydantic schema into a task prompt
- Spawn an isolated session on the configured OpenClaw gateway
- Parse the JSON response from the agent
- Validate against the declared output model
- Publish the validated artifact to the blackboard
If the response contains malformed JSON (e.g., wrapped in markdown fences), the engine automatically issues a repair prompt before failing. This single transparent retry improves reliability without complexity.
| Flock Feature | OpenClaw Compatibility |
|---|---|
| Typed artifact routing | Fully supported |
| Visibility controls | Fully supported |
| Fan-out publishing | Fully supported |
| Predicates and where filters | Fully supported |
| JoinSpec / BatchSpec | Fully supported |
| Workflow conditions (Until DSL) | Fully supported |
| OpenTelemetry tracing | Fully supported |
| Context providers | Fully supported |
| Dashboard visualization | Supported (with engine badge) |
Getting Started
Gateway Configuration
Flock supports two configuration approaches: explicit gateway registration and environment-based auto-discovery.
# Explicit configuration
from flock import Flock, OpenClawConfig, GatewayConfig
flock = Flock(
openclaw=OpenClawConfig(
gateways={
"codie": GatewayConfig(
url="https://openclaw.internal.example.com:19789",
token_env="OPENCLAW_CODIE_TOKEN",
)
}
)
)
# Environment-based auto-discovery (recommended for production)
# Expects: OPENCLAW_<ALIAS>_URL and OPENCLAW_<ALIAS>_TOKEN
flock = Flock(openclaw=OpenClawConfig.from_env())Defining OpenClaw Agents
The openclaw_agent() method provides the same fluent API as agent():
from pydantic import BaseModel, Field
from flock.registry import flock_type
@flock_type
class FeatureSpec(BaseModel):
feature: str = Field(description="Feature to implement")
requirements: list[str] = Field(description="Key requirements")
@flock_type
class Implementation(BaseModel):
code: str = Field(description="The implemented code")
explanation: str = Field(description="Approach explanation")
implementer = (
flock.openclaw_agent("codie")
.description("Implements features from specifications")
.consumes(FeatureSpec)
.publishes(Implementation)
)Mixed Pipelines
OpenClaw agents compose with native LLM agents in the same workflow. The blackboard handles artifact routing regardless of the compute source:
# OpenClaw agent: code generation (tools, web search, multi-step reasoning)
writer = flock.openclaw_agent("codie").consumes(Spec).publishes(Code)
# Native LLM agent: structured code review (single LLM call)
reviewer = flock.agent("reviewer").consumes(Code).publishes(Review)
# Publish and execute
await flock.publish(spec)
await flock.run_until_idle()Per-Agent Configuration
# Increase timeout and retries for complex tasks
researcher = flock.openclaw_agent("claude", timeout=300, retries=2)
.consumes(Question)
.publishes(Report)Further Resources
- Find more examples in the GitHub Repo
- All the concept details & documentation are available here
What You Can Build
The real power of this integration isn’t replacing one agent with another — it’s workflows that were previously impossible or required extensive custom engineering.
Autonomous Code Review with Real Test Execution
A native LLM agent can review code, but it’s guessing about correctness. An OpenClaw agent can actually run the tests. Combine both in a Flock pipeline:
# OpenClaw: implements the feature (file access, web search, code execution)
implementer = flock.openclaw_agent("codie").consumes(FeatureSpec).publishes(Implementation)
# OpenClaw: runs the test suite, captures real output
tester = flock.openclaw_agent("codie").consumes(Implementation).publishes(TestResults)
# Native LLM: reviews code quality with actual test evidence
reviewer = flock.agent("reviewer").consumes(Implementation, TestResults,
join=JoinSpec(by=lambda a: a.correlation_id)
).publishes(CodeReview)The reviewer doesn’t hallucinate about whether tests pass — it has the real output. The blackboard’s join operation ensures the reviewer waits for both the implementation and test results before synthesizing its verdict. This workflow is impossible in OpenClaw alone (no typed joins) and unreliable with native agents alone (no test execution).
Parallel Research with Intelligent Synthesis
Need to research a topic from multiple angles? Fan out to multiple OpenClaw agents, each with web search and different research briefs, then synthesize:
# Fan-out: 5 OpenClaw researchers investigate different angles in parallel
researcher = flock.openclaw_agent("claude").consumes(ResearchBrief).publishes(
Finding, fan_out=(3, 8) # 3-8 findings depending on what the agent discovers
)
# Batch: collect all findings, synthesize once complete
synthesizer = flock.agent("synthesizer").consumes(
Finding, batch=BatchSpec(size=5, timeout=timedelta(seconds=120))
).publishes(ResearchReport)Each OpenClaw agent searches the web, reads documents, and produces structured findings. Flock’s batch spec collects them and triggers synthesis only when enough evidence arrives or a timeout hits. The result is a research report backed by real web data — not hallucinated citations.
Content Pipeline with Live Data Enrichment
Content generation is good. Content generation backed by real-time data is better:
# OpenClaw: fetches current market data, competitor pricing, recent news
data_agent = flock.openclaw_agent("codie").consumes(ContentBrief).publishes(MarketData)
# Native LLM: writes the article using real data as source material
writer = flock.agent("writer").consumes(ContentBrief, MarketData,
join=JoinSpec(by=lambda a: a.brief_id)
).publishes(DraftArticle)
# Native LLM: reviews for accuracy against the source data
fact_checker = flock.agent("checker").consumes(DraftArticle, MarketData,
join=JoinSpec(by=lambda a: a.brief_id)
).publishes(FactCheckedArticle)The fact-checker has both the article and the original market data, so it can verify claims against real sources. This three-stage pipeline runs automatically — publish a ContentBrief and get a fact-checked article backed by live data.
Security-Scoped Multi-Tenant Workflows
When OpenClaw agents process sensitive data, Flock’s visibility controls ensure isolation without extra engineering:
# Each tenant's data is only visible to agents processing that tenant
processor = flock.openclaw_agent("codie").consumes(
CustomerRequest,
visibility=PrivateVisibility(scope="tenant") # Tenant-scoped isolation
).publishes(ProcessedResult)OpenClaw’s own security model is prompt-based — it relies on instructions to enforce boundaries. Flock’s visibility layer is architectural: agents physically cannot see artifacts outside their scope. This matters for compliance, multi-tenant SaaS, and any workflow handling sensitive data.
Error Handling
OpenClaw failures map to standard Python exceptions with clear retry semantics:
| Failure Mode | Exception Type | Automatic Retry |
|---|---|---|
| Gateway unreachable | RuntimeError | Yes |
| Request timeout | RuntimeError | Yes |
| Authentication failure (401/403) | ValueError | No |
| Invalid JSON response | RuntimeError | Yes (repair attempt) |
| Schema validation failure | RuntimeError | No (after repair) |
Dashboard Support
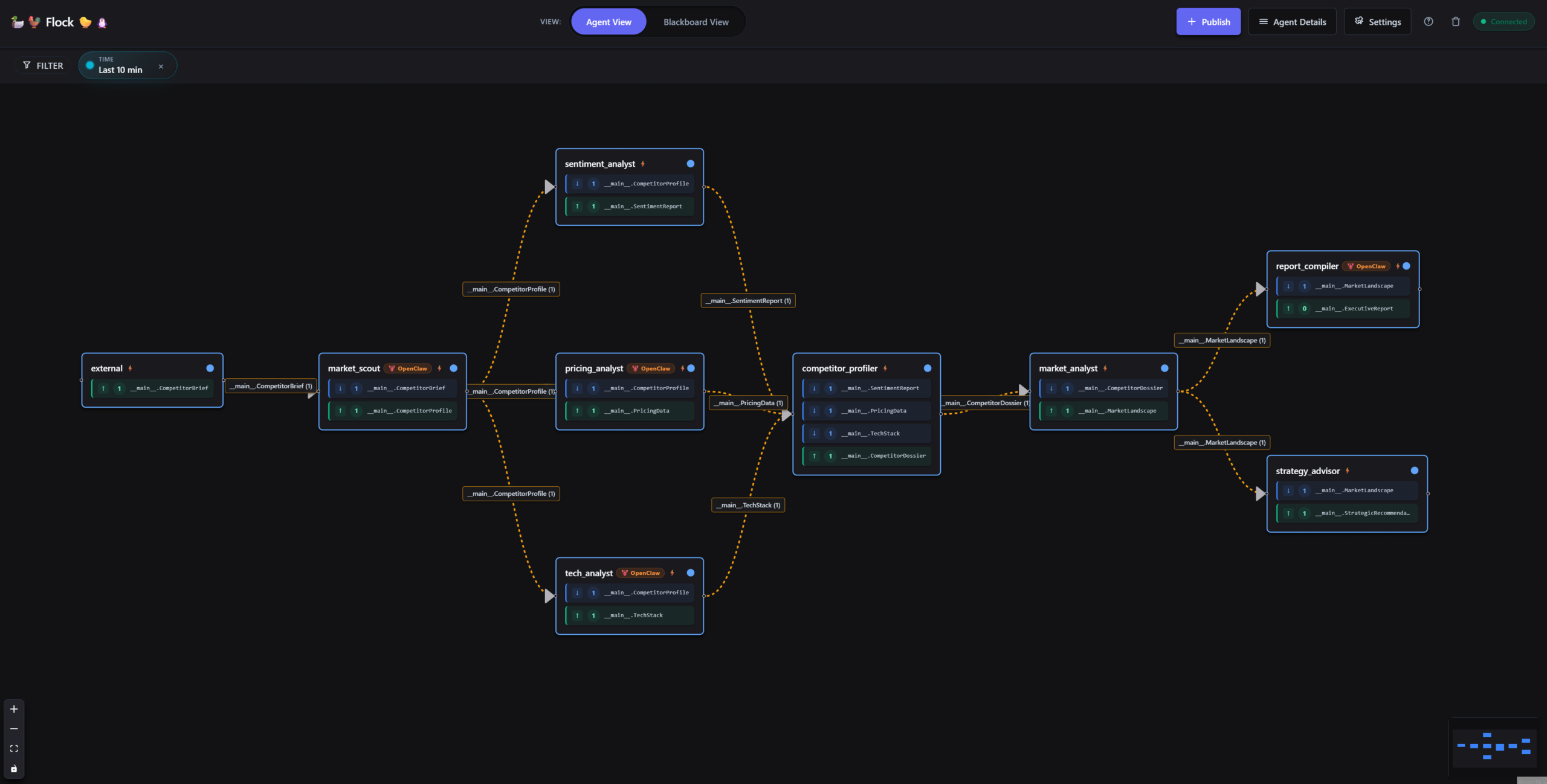
OpenClaw agents are automatically identified in Flock’s real-time dashboard. The graph builder detects the „openclaw“ label and displays a visual indicator alongside the agent name. All standard dashboard features, including status monitoring, artifact flow visualization, and WebSocket-driven live updates, work without additional configuration.
Roadmap
The current release delivers the core integration: OpenClaw agents as first-class Flock pipeline participants with full blackboard semantics. Beyond this foundation, we’re planning additional capabilities across three areas:
- Resilience & Control: Session mode for persistent conversations across invocations, exponential backoff for transient failures, concurrency limits per gateway, loop prevention safeguards, and deeper trace span integration for end-to-end debugging.
- Advanced Communication: Bidirectional publishing so OpenClaw agents can both consume and emit artifacts mid-execution, streaming output for long-running tasks, multi-gateway load balancing across OpenClaw instances, and capability discovery to automatically match agent skills to pipeline requirements.
- Ecosystem & Trust: Lease/claim workflows for coordinated multi-agent task ownership, OTLP export for integration with existing observability stacks, trust metadata on agent outputs, and verification primitives to validate agent behavior against expected contracts.
Running Agentic AI in a Secured Environment
Agentic AI systems like OpenClaw interact with real tools, real data, and real permissions. That’s what makes them powerful, and it’s why they need to run in a properly secured environment. This applies to any AI agent with access to email, file systems, calendars, or messaging platforms, not just OpenClaw.
General AI security best practices should be part of every agentic AI deployment: scoped permissions, network segmentation, credential management, input validation, and comprehensive logging. These are the same principles that apply to any system with privileged access. Agentic AI is no exception.
Flock helps by providing the enterprise integration layer around OpenClaw agents. Typed contracts validate every agent output before it enters the pipeline. Visibility controls scope data access per agent, per tenant, per role, all architecturally enforced. Circuit breakers and retry logic add operational resilience. This doesn’t replace securing the OpenClaw gateway itself, but it ensures that within your enterprise workflows, agent behavior is structured, observable, and governed.
The combination works: OpenClaw running in a secured environment for its powerful agent capabilities, Flock providing the orchestration layer that integrates those capabilities into enterprise tooling with the governance and compliance controls your organization requires.
Ready to build secure, enterprise-ready agentic AI? We help organizations design and implement agentic AI architectures that deliver productivity without compromising security and compliance. Book a call to start your journey.