What’s all the hype with Transformers? Part 3: Enter the Transformer Model
In our previous posts „What’s all the Hype with Transformers? The Trouble with Natural Language Processing“ and „What’s all the hype with Transformers? Part 2: Memory for RNNs„, we highlighted some of the issues of natural language processing, some of the methods and mechanisms that have been used to tackle these issues, and some of the limitations of these methods.
In this post, we will talk about the new, cool kid on the block: The Transformer Model. More specifically, we are going to talk about the architecture of the Transformer Model, how it works, and what makes it so special.
Contents
The Transformer Model
This is where the Transformer model comes in. The Transformer-Architecture sets out to tackle the limitations of RNNs by introducing a new architecture that can process data in parallel.
The most important part of the Transformer model is the Attention Mechanism.
Attention is all you need
To understand the Attention Mechanism, it is best to start with the following question:
„How do you define the meaning of a word?“
Seems simple, right? You just look up the word in a dictionary and read the definition. But wait a minute, how do you define the words in the definition? Aren’t we just defining words with other words?
This is where the idea of Attention comes in. To simplify, Attention is the idea that the information of a word is not only defined by the word itself but also by the words around it. So, the informational value of an element of a sequence is not only defined by the element itself but also in through the relation to the other elements in the sequence.
We therefore need a mechanism that can capture the relation between the elements of a sequence. (This leans on the idea of distributional semantics, which states: „You shall know a word by the company it keeps.“) So our new model needs some kind of „sensory“ organ that it can use to „look“ at the other elements of the sequence and decide how to combine their influence.
Input Representation
How does a Transformer model see the input sequence?
Internally, the input sequence consists of a series of vectors, where each vector represents a token in the input sequence. This vector is called the Embedding of the token and is made up of a series of numbers that represent the token in a high-dimensional space. Also, a Transformer model has a series of Positional Encodings that represent the position of the token in the input sequence.
So each element x^i of the input sequence is represented by a vector that contains information about the token itself and its position in the sequence:
x^i = Embedding(token_i) + Positional_Encoding(i)
Embeddings
How do we get the Embedding of a token? For our model to understand the meaning of a token, we need to represent it in a high-dimensional space. In this particular example, our token is a word in a sequence of text, so we need to represent it in a space where words with similar meanings are close to each other.
We do this by using a One-Hot Encoding of the token, which is then multiplied by a Word Embedding Matrix.
One-hot encoding is a way of representing a token as a vector of zeros and ones, where the position of the one represents the position of the token in the vocabulary.
So, for example, if we have a vocabulary of 10,000 words, the word „cat“ would be represented as a vector of 10,000 zeros and one at the position of the word „cat“ in the vocabulary.
The Word Embedding Matrix is a matrix that contains the embeddings of all the words in the vocabulary. This matrix is learned during the training of the model, and it is used to represent the tokens in the input sequence. So, the Embedding x^i_embedding of a toe token x^i is calculated as follows:
x^i_embedding = One_Hot_Encoding(x^i) * Word_Embedding_Matrix
Positional Encodings
Since we now want to process our sequence in parallel, we need to keep track of the positions of our tokens. RNNs don’t have this problem, as they are „forced“ to process the sequence in order, so they can keep track of the position of the tokens by the order in which they are fed into the model. Our Transformer model, however, needs to process the sequence in parallel, because we want the model to be faster and also we want to be able to calculate the relation each token of the sequence has to all the other tokens in the sequence. Therefore, we need to add a Positional Encoding to each token in the input sequence. This will represent the position of the token in the sequence and add that fact to the calculations of the model.
An often-used technique for computing the position of a token in the sequence is to use a Sine and Cosine function with different frequencies. Because these functions describe waves, neighboring tokens will have similar Positional Encodings, which will help the model to understand the order of the tokens in the sequence.
A popular technique for calculating these positional indexes is to use 2*(i//2) for the even indexes and 2*(i//2) + 1 for the odd indexes. This way, we calculate a Vector of the same length as the Embedding of the token, which we can then add to the Embedding of the token to get the final representation of the token in the input sequence. The calculation of the vector is done as follows:
PE(pos, 2i) = sin(pos _ w / 10000^(2i/d_model)), if i is even PE(pos, 2i) = cos(pos _ w / 10000^(2i/d_model)), if i is odd
d_model is the dimensionality of the model, and pos is the position of the token in the sequence. w is a hyperparameter that determines the frequency of the sine and cosine functions. This parameter can be freely chosen before training the model.
The Attention Mechanism
So, we now transformed a sequence of tokens into a series of vectors that represent the tokens and their position in the sequence. Where do we go from here?
Since we now have a sequence of vectors, filled with information about the tokens and their position in the sequence, we can now calculate the relation between the tokens in the sequence.
This is done by the Attention Mechanism, which is the core of the Transformer model. It is a mechanism that allows the model to „look“ at the other tokens in the sequence and decide how to combine their influence. Think of the Attention Mechanism as the eyes of the model, which it can use to „look“ at the other tokens in the sequence and decide how to combine their influence.
The idea is to represent the relation that each token of the sequence has to all the other tokens in the sequence as a so-called Context-Vector. Again, going back to our analogy of the dictionary, the meaning of a token is defined by its relation to the other tokens in the sequence.
To construct this Context-Vector y_i for a token x^i, we need to calculate the relation of the token x^i to all the other tokens in the sequence.
The Context-Vector y_i is calculated as follows: y_i = sum(\alpha_ij * x^j).
The \alphaij are the Attention Weights, which represent the relation of the token x^i to the token x^j. These weights are calculated based on the scalar product of the Embeddings of the tokens x^i and x^j:
alpha_ij = softmax(x^i * x^j). = exp(x^i * x^j) / sum(exp(x^i * x^k)).
This calculation is done for all the tokens in the sequence, which results in a series of Attention Weights for each token in the sequence. These weights are in the range of 0 to 1, and can be viewed as a distribution of probabilities since they sum up to 1. This is done to ensure that the values in the Context-Vector do not become too large or too small, which would make the model unstable.
In calculating the Context-Vector y^i, the Attention Weights usually dominate the calculation, because when calculating the scalar product between a vector x^i and the Attention Weights alpha^ij, the Attention Weights are usually much larger than the vector x^i.
This means that the relation that a token has to all other tokens in the sequence is considered to be more important than the intrinsic information of the token itself while also allowing each token to pass on some information of its own.
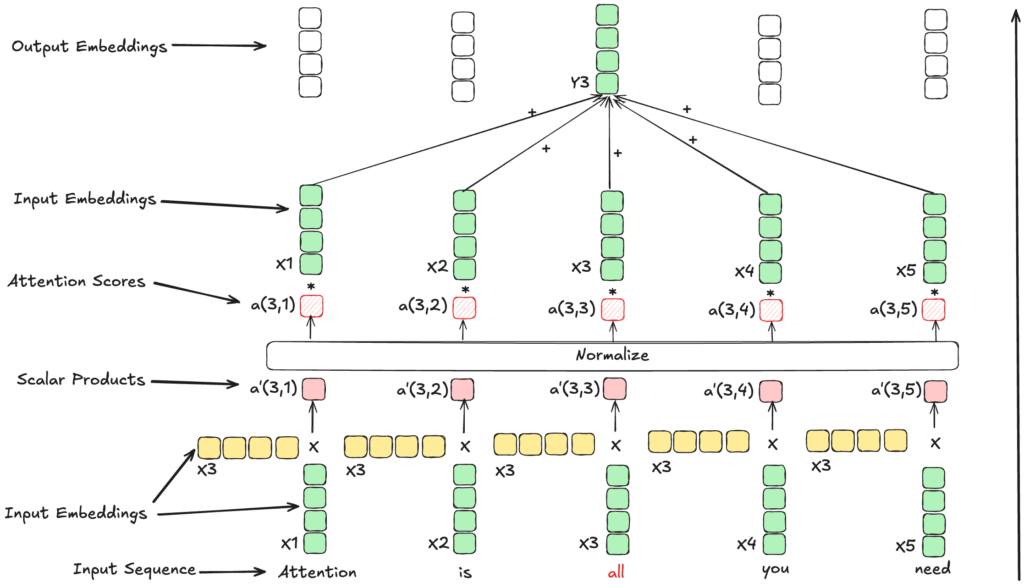
For each Input-Embedding x^t, the model calculates an Output y^t as a weighted sum of all the Input-Embeddings x^i, where the weights are calculated by the Attention Mechanism. In this specific instance, we show the calculation of the Context-Vector y^3 for the token x^3 as a normalized scalar product of the Embeddings of the tokens x^1, x^2, x^3, x^4, and x^5. This whole process is called Self-Attention, because the model is attending to itself, meaning that it is calculating the relation of each token to all the other tokens in the sequence.
Regular Self Attention
Regular Self-Attention is the simplest form of the Attention Mechanism and is an extension of the rudimentary Attention Mechanism described above. The difference is that here, we apply a linear transformation to the Embeddings of the tokens before calculating the Attention Weights. This is done to direct attention to different aspects of each embedding. Here we calculate three additional vectors for each token in the sequence: The Query Vector, the Key Vector, and the Value Vector.
- The Query Vector (here denoted as q_i) represents the question, for which relation (context) for a given token the model is looking for.
- The Key Vector (here denoted as k_i) represents the information the token stands for.
- The Value Vector (here denoted as v_i) represents the information the token passes on to the other tokens in the sequence (think for example the word ‚was‘ will probably influence the tense of the sentence).
These three vectors are calculated by multiplying the embedding of the token with three different weight matrices, which are learned during the training of the model.
The Query Vector q_i, the Key Vector k_i, and the Value Vector v_i are calculated as follows: q_i = x^i * W^Q k_i = x^i * W^K v_i = x^i * W^V
Where W^Q, W^K, and W^V are the weight matrices that are learned during the training of the model and are initialized randomly before being adjusted during the training process. This means that the model learns which aspects of the token are important for the calculation of the Attention Weights. (In the case of a Large Language Model, imagine it as the model learning the definitions for words, grammar, and context.)
There are more specialized and more complex forms of the Attention Mechanism, but this is the basic idea behind the Attention Mechanism in the Transformer model.
Multi-Head Attention
Now that we have seen the „internal“ anatomy of a single Attention Mechanism, let’s take a look at the „external“ anatomy of the Attention Mechanism. In the real world, we don’t just have one Attention Mechanism, but many Attention Mechanisms that work together to process the input sequence. Think of it as the model looking at a sequence from different angles to get a better understanding of the sequence. (Kinda like you would look at a painting from different angles to get a better understanding of the painting.)
This is called Multi-Head Attention, because each singular Attention Mechanism is called a Head. Each of these Attention Heads is responsible for a different aspect of the input sequence, and they work together to process the input sequence. These Attention Heads possess different Query, Key, and Value Vectors, which allows them to focus on different aspects of the input sequence. This is done because Multi-Head Attention only makes sense if it can be guaranteed that each Attention Head focuses on a different aspect of the input sequence.
This is why the Query, Key, and Value Weight Matrices are different for each Attention Head, which allows the model to learn different aspects of the input sequence. They are initialized randomly before being adjusted during the training process. Interestingly, this leads to the effect that the precise nature of the aspect each Attention Head focuses on cannot be determined before the training process.
When using Multi-Head Attention, the input sequence is split into h different parts, where h is the number of Attention Heads.
The following illustration shows the principle of Multi-Head Attention:
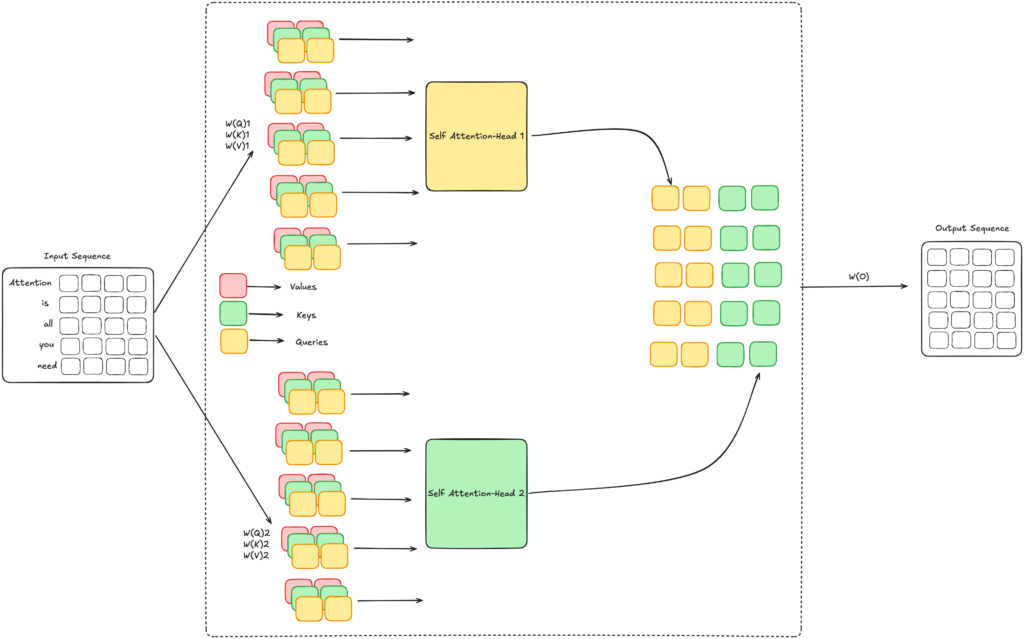
Here, you can see that the input sequence is split into h different parts, where each part is processed by a different Attention Head, before the results are combined to form the final output of the Attention Mechanism. The Output of the Attention Mechanism has the same dimensionality as the input sequence, which allows it to be fed into the next layer of the model. This also allows us to chain multiple layers of Multi-Head Attention together, which allows the model to process the input sequence in a more complex way. (If you think about it, you are probably doing something similar right now: Your eyes are focusing on different parts of the screen (the letters of the text), passing the processed input on to your brain, which then runs object detection on the processed input signal, detecting the words and passing the processed signal on to your language center, which then processes the signal and produces the understanding of the text.)
Transformer Blocks
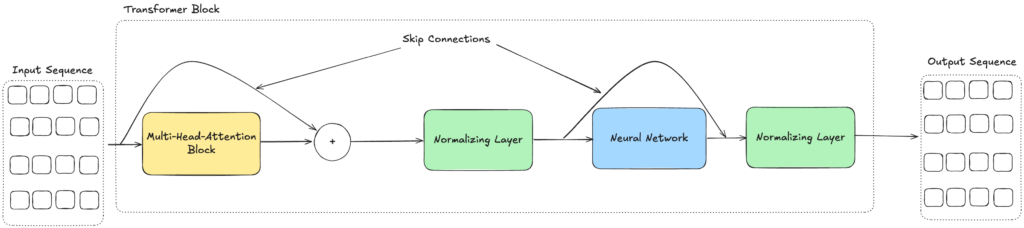
The Transformer Block is the basic building block of the Transformer model. Each Block contains two components: The Multi-Head Attention Mechanism and a Feed-Forward Neural Network.
In this unit, the Multi-Head Attention Mechanism enriches the Input sequence with context information before passing it on to the Feed-Forward Neural Network, which processes the sequence further, extracting additional information from the sequence. In addition to that, the Transformer Block contains two Normalization Layers that normalize the output of the Multi-Head Attention Mechanism and the Feed-Forward Neural Network. This is done to speed up the training process and to stabilize the model.
Also, sometimes so-called Skip Connections are used to pass the input sequence directly to the output of the Transformer Block. This is done to ensure that the model does not lose information during the processing of the sequence.
The following illustration shows the internal anatomy of a Transformer Block:
The limited size of the Input Sequence and Context Windows
And now, we finally arrive at the main limitation of Transformer models and a very important technical aspect to consider when interacting with these models. Since an Attention Mechanism must calculate the relation of each token to all the other tokens in the sequence in parallel, the size of the input sequence has to be known beforehand.
While RNNs can process sequences of arbitrary length, Transformer models have a fixed size of the input sequence, which is determined by the number of tokens an Attention Mechanism can process in parallel. (This is usually referred to as the Window Size of the model.)
While there exist techniques to process longer sequences with a Transformer model, such as Sliding Window Attention or Long-Range Attention, every Transformer model has a fixed maximum size of the input sequence. These Window Sizes limit the amount of data the model can process at any given time, be that the length of a conversation, the size of an image, or the length of a time series.
These so-called Context Windows need to be taken into consideration when choosing a Transformer model for a specific task, as they can limit the model’s ability to process the input data. For example, the model gpt4-turbo has a Context Window of 128 thousand tokens, which means that it can process 128 thousand tokens at a time. This is a very large Context Window, but it is still limited by the size of the input sequence.
Improved Performance
The main advantage of the new Architecture of Transformer models is the fact that now the model can not only process data in more detail but also in parallel. This is especially important because that means GPUs can now train the model much faster than before, resulting not only in reduced cost and training time but also in the ability to train much larger models.
These larger models can then be used to process more complex data much faster than their RNN counterparts, allowing the same hardware to run much more complex (therefore presumably „smarter“) models than before.
This fact is the driving force behind the current AI revolution. Not only have humans developed ever more powerful hardware but the improvements to the Transformer model have allowed us to train larger and smarter models which can process more complex data in less time than ever before.
This allows us to integrate AI into new and exciting applications, (in fact, it is hard to find an application that does NOT advertise the use of AI in some form or another) and to create new and exciting products that were not possible before. But this has also resulted in new challenges.
Challenges
Limited Knowledge
At the end of the day, any Large-Language Model, or any Transformer Model for that matter is just a mathematical function that takes an input and produces an output. This mathematical function has been adjusted using a large set of training data.
The consequence of this is that once the model has finished training and has been published, it is „locked“ in so to speak. This means that the model can only produce predictions based on the data it has been trained on. In practical terms, this leads to the fact that the model is only „aware“ of the knowledge that has been present in the training data.
For example:
gpt-3.5-turbo was trained on a dataset containing knowledge up to the year 2021. This means that if I were to ask gpt-3.5-turbo about the current weather, there is no way for the model to know the current weather. It will certainly try its best to give me a meaningful answer, but without any possibility to access additional sources of information, it will at best be limited to saying that it cannot provide me with the current weather and at worst give me a completely wrong answer.
This is an issue that is not unique to Transformer Models but is a general problem with all AI models. However, as the use of AI models becomes more widespread, this issue is something we as software developers need to be aware of when we are trying to integrate AI models into our applications.
Limited Context
Thanks to the powerful Attention-Mechanisms, we can circumvent the issue of Limited Knowledge in our AI model. The solution seems simple: Just add the missing data you want the model to know about into the prompt you give the model. This practice is an important part of why we perform so-called „Prompt Engineering“ when we are working with AI models. However, as we have discussed previously, the model has a fixed Context Window, which limits the amount of data the model can process at any given time.
So, we can’t just copy-paste all of Wikipedia into the prompt and call it a day, this would be too much data for the model to process at once and we would not get a meaningful answer, or even worse, we would decrease the quality of the model’s predictions. Any application we build that incorporates an AI model needs to be aware of this important limitation. When we just had to deal with RNNs, this was not a problem, since the architecture of an RNN allows it to theoretically process sequences of arbitrary length.
If we want to leverage the power of the new Transformer Models however, we need to carefully design our application in such a way that we can still provide the model with the necessary information from a potentially very large pool of data, while still respecting the limitations of the model’s Context Window.
These two problems have given rise to a new type of application architecture, which is specifically designed to leverage the power of Transformer Models, called „Retrieval Augmented Generation“, something which my colleague Nico Meisenzahl has already alluded to in his blog post, „Personalizing AI – How to Build Apps Based on Your Own Data“. This specific architecture is currently all the rage in the field of Conversational AI and Natural Language Processing and we will take a closer look at the general ideas behind this architecture, its advantages, and its limitations in a future blog post.
Conclusion
Transformer Models are a new and promising technology for the field of AI and Natural Language Processing, allowing us to not only create larger and faster models but also process data in more depth and detail than ever before.
This revolution in AI has been made possible by the introduction of the Attention Mechanism, which allows a model to process data more computationally efficient, faster, and in finer detail than ever before. This new architecture also allows AI engineers to build larger and more complex neural architectures, while also leveraging existing hardware more efficiently, and allowing these new models to be trained much faster, and therefore more cost-effective than their RNN counterparts.
These new models come with their own set of challenges and limitations however, which need to be taken into consideration when building applications that leverage the power of these new models. The limited size of the input sequence, because of the Attention-Mechanism, is the chief limitation one needs to account for when integrating these models into an application.
There are however ways to circumvent these limitations. Thanks to the powerful Attention Mechanisms, we are not only able to use very powerful new AI models, but are also able to adapt these models to our specific needs, without having to worry about retraining the model or adjusting the model’s architecture.
Outlook
This concludes our little mini-series on Transformer Architecture and its practical implications for the field of Natural Language Processing. In our next blog post, we will take a closer look at the new architecture of „Retrieval Augmented Generation“ and how it can be used to build truly unique applications that leverage the power of Transformer Models to their fullest potential.