Personalizing AI – How to Build Apps Based on Your Own Data
Generative AI is on everyone’s lips. Both software providers and companies with in-house developers have started to implement intelligent applications and functions based on generative AI models, such as those from OpenAI. One of the best ways to maximize the potential of smart applications is to rely on your own data. In this post, we’ll delve into the available patterns and techniques for personalized AI-based applications using OpenAI, along with Azure services and Open Source.
What you will learn in this post:
- The benefits of using your internal data
- Available Patterns and techniques
- How Azure and Azure OpenAI can help
- The power Open Source with Semantic Kernel
The benefits of using your internal data
Integrating contextual data into AI-based applications can pave the way for more customized and efficient user experiences. can provide tailored functions that cater to specific user requirements. Additionally, utilizing our own data increases the accuracy of feedback and interaction from users, optimizing the user experience.
When you set up a PrivateGPT (a private ChatGPT instance based on private models) instance for privacy and security reasons, the integration of private data sources also leads to personalized conversation experiences and a tailored user experience. You ensure the confidentiality of your data by making it accessible only to authorized users within your company for internal use.
Available Patterns and techniques
This section introduces you to the available development patterns and techniques that enable you to integrate data sources into your AI-based applications.
Invest in Prompt Engineering
Prompt engineering is the foundation for interacting with generative AI models and is therefore a crucial technique for developing successful AI-based applications, as it helps to ensure that the AI model responds to the specific needs and requirements of the requester. It doesn’t matter if it’s a user or an API.
By crafting effective prompts, you can improve the accuracy and relevance of the generated content. But you also have to compensate for the weaknesses of the model by, for example, providing further input data that helps the model respond with a better answer. This also allows you to inject your own contextual data and helps the model generate more informed and up-to-date responses.
As the tokens used to craft the prompt are limited, you are also bound by how much data and content you can add. This is where the next pattern comes in.
Retrieval Augmented Generation (RAG) Pattern
The goal of the Retrieval Augmented Generation (RAG) pattern is to enable the generation of high-quality and relevant responses by first retrieving context-relevant information from a large dataset and then using it to guide the generation of new content. This involves several key components, like prompt engineering, embeddings and vector database, semantic search, and web search.
In the following example, a user asks for a WiFi password. Because this application was implemented using the RAG pattern, the answer will contain the right WiFi password. Of course, the user could also be another application or API.
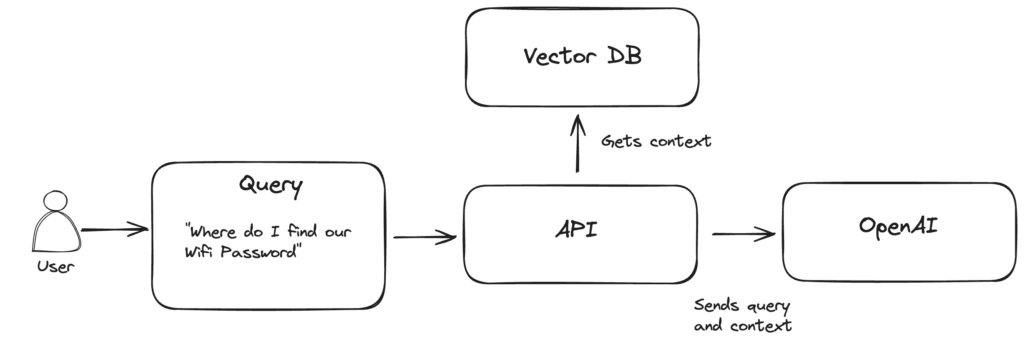
Normally, the LLM (Large Language Model) would answer with an incorrect password. This is because the model is not able to know the correct WiFi password. However, since the RAG pattern is used here, the user’s query is enriched with helpful content from a vector database. The query and context are then used as a prompt for the model.
This works because the vector database contains a multidimensional representation of the data fed in, such as, in this example, an internal wiki. Those vectors are called Embeddings and are used to cluster and classify data for searching and recommendations.
As mentioned above, using vector databases is just one example of how to implement this pattern.
These are the advantages of using the RAG pattern:
- Cost-effective and faster implementation due to fewer tokens being used in prompts
- Context-aware resonances with the latest information
- Improved user confidence due to accurate information containing quotations or references
- More control and simpler implementation
Later in this post, you will learn how to implement the RAG pattern on Azure.
Fine-tuning a model
Another way to incorporate your specific data is by fine-tuning a model. However, you should first invest in your prompt engineering, prompt chaining, function calling, and also validate the RAG pattern based on your needs. Both options are very powerful and support most, if not all, common use cases.
Good use cases for fine-tuning include controlling the model to output content in a specific and customized style, tone, or format, or relying on any industry-specific generic data. A fine-tuned model optimizes based on the few-shot learning approach, the weights of the model based on your data. Therefore, preparing and validating your training data is key to success.
The benefits of a fine-tuned model contain:
- Higher quality results compared to prompting
- Train with more examples than can fit in one prompt
- Token savings due to shorter prompts
- Reduced latency times for requests
How Azure and Azure OpenAI can help
Azure Cloud provides you with a variety of AI- and ML-based services. From Azure OpenAI, Azure Machine Learning, Meta Llama 2 models, and corresponding and supporting services.
In this post, we focus on Azure OpenAI on your data (currently in preview), which allows you to integrate Azure OpenAI with your own internal data via the RAG pattern described above. Azure OpenAI on your data works with, for example, Azure AI Search to determine what data to retrieve from the designated data source based on the user input and conversation history provided. This data is then augmented and passed to the OpenAI model as a prompt.
Thereby, Azure AI Search supports keyword, semantic, and vector searches, document-level access control, and schedule automatic index refreshes.

An example API call against Azure OpenAI with Azure AI Search as a data source using curl:
curl -i -X POST YOUR_RESOURCE_NAME/openai/deployments/YOUR_DEPLOYMENT_NAME/extensions/chat/completions?api-version=2023-06-01-preview \
-H "Content-Type: application/json" \
-H "api-key: YOUR_API_KEY" \
-d \
'
{
"temperature": 0,
"max_tokens": 1000,
"top_p": 1.0,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "YOUR_AZURE_COGNITIVE_SEARCH_ENDPOINT",
"key": "YOUR_AZURE_COGNITIVE_SEARCH_KEY",
"indexName": "YOUR_AZURE_COGNITIVE_SEARCH_INDEX_NAME"
}
}
],
"messages": [
{
"role": "user",
"content": "Where do I find our Wifi password?"
}
]
}
'In addition, Azure OpenAI on your data also supports Azure Cosmos DB for MongoDB vector search, Azure Database for PostgreSQL Flexible Server with pgvector, Azure Blob Storage (for images using GPT-4 vision) or any URLs and web pages as data ingest source.
For a first easy implementation or proof of concept, also Azure OpenAI Studio allows ingesting data via Textfiles, Markdown, HTML, PDF, and Microsoft Office documents (Word, PowerPoint).
The power Open Source with Semantic Kernel
Semantic Kernel is an open source SDK that allows developers to build AI-based applications. It is a highly extensible SDK that can be used with models, for example, from OpenAI, Azure OpenAI, and Hugging Face, and supports C#, Python, and Java code. It allows you to define and orchestrate plugins that can be chained together in just a few lines of code. Furthermore, Semantic Kernel abstracts the underlying model API, which allows switching models or versions easily with minor code changes.

With Semantic Kernel Memory you can make use of the RAG pattern. Currently, the following data stores and integrations are available:
- Conventional key-value pairs with a one-to-one match of a key
- Conventional local storage from your local disk
- Semantic memory search
With the last one being the most powerful and support for a variety of vector databases in the Azure and open source ecosystem.
Now it’s time to get your hands dirty and build your first AI-powered application!