Flock & Dapr: Resilient Cloud-Native Agent Swarms
Contents
- What is Dapr?
- Why we built this integration
- The integration surface is small
- One workflow, three backends
- One-time setup
- In-memory: the local baseline
- PostgreSQL: durable and transactional
- Redis encrypted: hardened for cloud-native deployment
- Capabilities, not promises
- Why this matters
- Dapr or SQLite? A quick decision guide
- Building production agent systems?
Anyone who has pushed agent workflows past a demo runs into the same wall: building the agents is the easy part. Running them reliably in production is not. Shared state needs to survive restarts, there needs to be a clean path to distributed execution, retries and failures need to be handled without bespoke adapter code for every backend, and the storage story needs to evolve from local development to production without a rewrite. That is exactly the wall we hit as we pushed Flock toward more serious workflows.
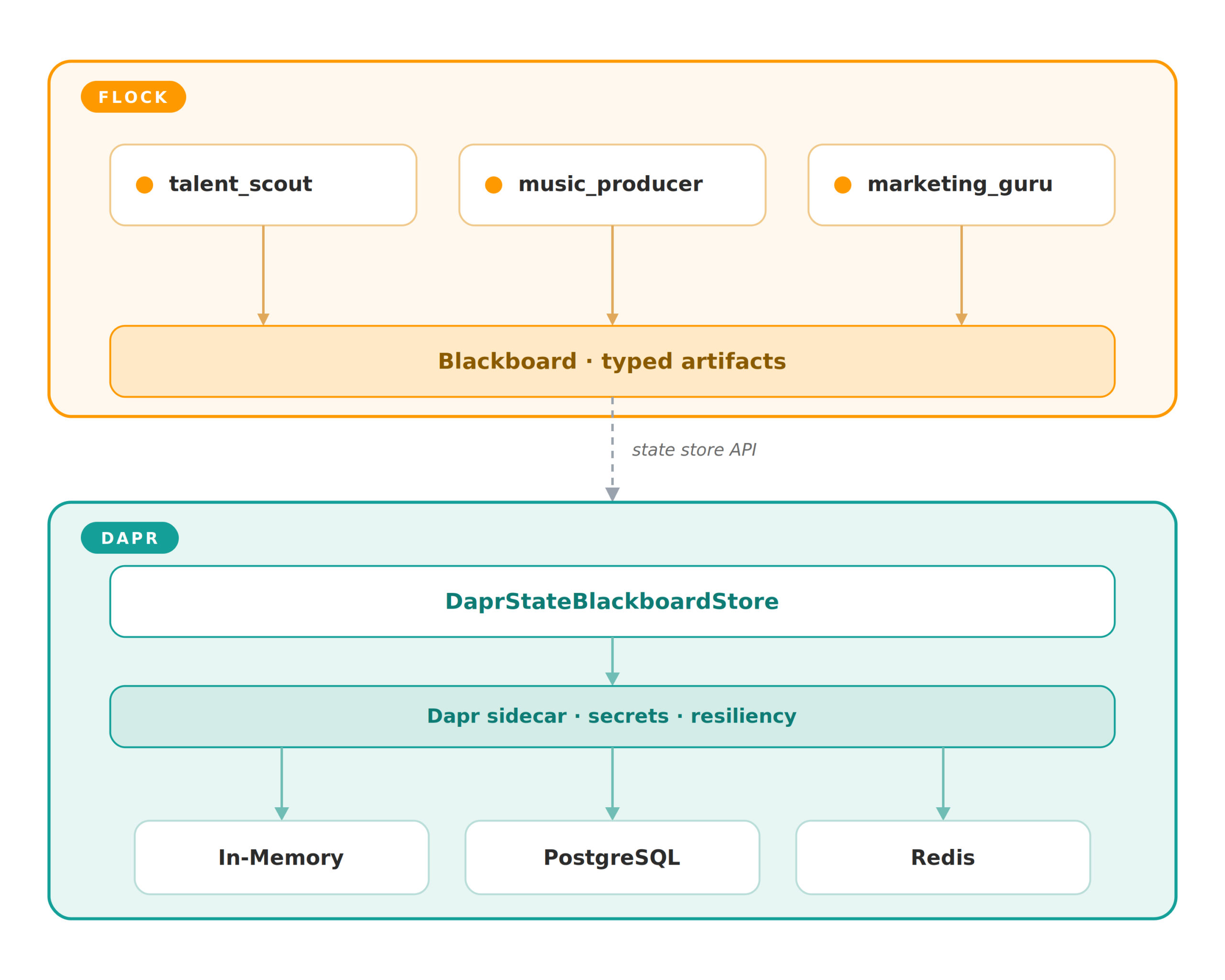
Flock is built around a blackboard model. Agents publish and consume typed artifacts, and the orchestration layer decides what should run next. That design already aligns with cloud-native thinking: low coupling, clear contracts, and small pieces that can be swapped independently. What it was missing was a production-grade home for the blackboard itself. That is exactly where Dapr fits, and it is what we shipped in Flock 0.5.600, a Dapr integration, available as an optional flock-core[dapr] extra.
What is Dapr?
Dapr is a portable, event-driven runtime that exposes cross-cutting building blocks, things like state management, pub/sub, secrets, and resiliency, over a local sidecar. Your application talks to a stable Dapr API, and Dapr talks to the actual backend, so the application code never learns which database, key-value store, or secret manager sits underneath. It is a CNCF-graduated project with a large component ecosystem.
More recently, Dapr has grown a set of first-class agent integrations aimed squarely at agentic frameworks. They add the production concerns those frameworks tend to skip: durable execution, portable agent context and memory through the State Management API, secure agent-to-agent communication, and secure agent identity. Flock uses one of those building blocks, the state store, as an optional distributed backend for the blackboard.
Why we built this integration
Agent systems look simple until the first production requirement shows up. Then the list starts growing quickly: shared state must survive restarts, multiple instances may need to see the same blackboard, secrets should not live in code, writes should be resilient, and different environments may prefer different storage backends.
At that point, you have two options. You can write a bespoke storage adapter for every backend you want to support and own all of the retry logic, encryption, and secret handling that comes with each one. Or you can delegate that operational layer to something purpose-built. We chose the second because those are exactly the problems Dapr already solves for cloud-native systems.
The result is a much cleaner boundary. Flock owns agent logic, typed artifacts, routing, and orchestration. Dapr owns state-store access, backend portability, retries, encryption, and backend-specific capabilities such as transactions, ETags, query support, or TTL where the chosen store supports them. Your application code stays mostly unchanged while the infrastructure underneath becomes more capable.
For the teams building on Flock, that boundary turns into concrete benefits. You can start on a local sandbox and grow to production without rewriting the swarm. You do not have to pick a storage backend on day one and live with that decision forever. Secrets and resilience policies live in infrastructure instead of glue code. And the same workflow runs on an in-memory store, on PostgreSQL, or on encrypted Redis with almost no code churn. If your team is not ready for a distributed backend at all, Flock still ships a single-node persistent blackboard, and we come back to when to use which at the end.
The integration surface is small
The best sign that an integration is healthy is that it stays small. In Flock, the Dapr integration is intentionally thin. The core pieces are DaprStateBlackboardConfig, DaprStateBlackboardStoreClientConfig, and DaprStateBlackboardStore. The swap point is the store= argument when you create Flock.
from flock import Flock
from flock.storage.dapr import (
DaprStateBlackboardConfig,
DaprStateBlackboardStore,
DaprStateBlackboardStoreClientConfig,
)
client_config = DaprStateBlackboardStoreClientConfig(
dapr_grpc_endpoint="localhost:50001",
)
store_config = DaprStateBlackboardConfig(
store_name="flockstate",
supports_transactions=True,
supports_etag=True,
consistency="strong",
client_config=client_config,
)
store = DaprStateBlackboardStore(config=store_config)
flock = Flock(
model="openai/gpt-4.1",
store=store,
)
That is the architectural win in one snippet. The agents do not know which backend is underneath them. The blackboard contract stays the same. Only the Dapr component definition and a few capability flags change. You can read the full setup in the Dapr State Store guide.
One workflow, multiple backends
To make the portability claim concrete, we run one small agent team across three different backends without touching the application logic. The team is deliberately playful:
- A
talent_scoutlooks for promising musicians based on aBandConceptand produces a cohesiveBandLineup. - A
music_producertakes thatBandLineupand designs anAlbumaround it. - A
marketing_guruturns theAlbumintoMarketingCopyand handles the PR side of things.
Here are the typed artifacts that pass through the blackboard as these three agents interact:
@flock_type
class BandConcept(BaseModel):
genre: str = Field(description="Musical genre (rock, jazz, metal, pop, etc.)")
vibe: str = Field(description="The band's vibe or aesthetic")
target_audience: str = Field(description="Who should love this band?")
@flock_type
class BandLineup(BaseModel):
band_name: str = Field(description="Cool band name")
members: list[dict[str, str]] = Field(description="Members with their roles")
origin_story: str = Field(description="How the band formed", min_length=100)
signature_sound: str = Field(description="What makes their sound unique")
@flock_type
class Album(BaseModel):
title: str = Field(description="Album title in ALL CAPS")
tracklist: list[dict[str, str]] = Field(
description="Songs with titles and brief descriptions",
min_length=8, max_length=12,
)
genre_fusion: str = Field(description="How this album blends genres")
standout_track: str = Field(description="The track that'll be a hit")
production_notes: str = Field(description="Special production techniques")
@flock_type
class MarketingCopy(BaseModel):
press_release: str = Field(description="Press release for the album", min_length=200)
social_media_hook: str = Field(description="Catchy social post", max_length=280)
billboard_tagline: str = Field(description="10-word tagline", max_length=100)
target_playlists: list[str] = Field(
description="Playlists to pitch to", min_length=3, max_length=5,
)
The three agents are just as declarative:
talent_scout = (
flock.agent("talent_scout")
.description("A legendary talent scout who assembles perfect band lineups")
.consumes(BandConcept)
.publishes(BandLineup, visibility=PublicVisibility())
)
music_producer = (
flock.agent("music_producer")
.description("A visionary music producer who creates debut album concepts")
.consumes(BandLineup)
.publishes(Album, visibility=PublicVisibility())
)
marketing_guru = (
flock.agent("marketing_guru")
.description("A marketing genius who writes compelling promotional material")
.consumes(Album)
.publishes(MarketingCopy, visibility=PublicVisibility())
)
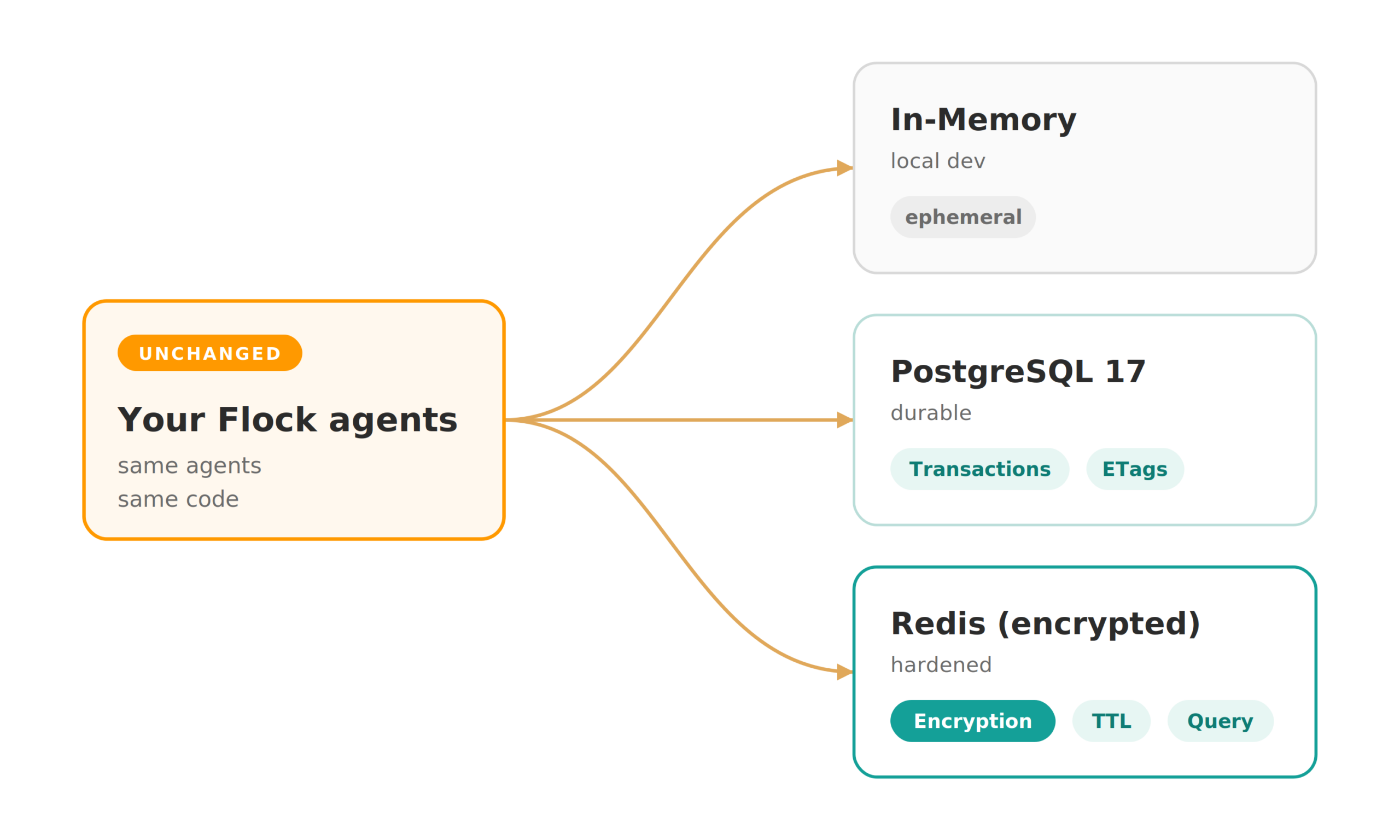
This is the whole agent. From here on, nothing in this code changes. The only thing that changes is the infrastructure Dapr sits on top of. We move through three backends: in-memory for fast local development, PostgreSQL for a durable test deployment, and encrypted Redis for a hardened production profile. As your swarm evolves, you can start small and swap the backend depending on your needs, without locking yourself into one path early.
One-time setup
Everything below runs through the Dapr CLI, so the local setup is two commands:
pip install "flock-core[dapr]"
dapr init
The first command pulls in Flock plus the optional Dapr dependencies. dapr init then installs the Dapr runtime and its local control plane, the background services (placement and scheduler) that the sidecar relies on. From here, each backend is a small component file plus a couple of Flock capability flags. If you would rather wire the sidecar, placement, and scheduler yourself, the repository’s examples/12-dapr ships full Docker Compose stacks. We use the CLI here to keep the moving parts visible.
In-memory: the local baseline
The in-memory backend is the simplest version, and we use it here to establish the Dapr code path before attaching a real store. For actual single-node development, you would normally reach for Flock’s built-in SQLite blackboard instead, which we cover in the decision guide at the end; in-memory earns its place only as the smallest possible wiring example. The story is intentionally boring in the best way: no encryption, no transactions, no TTL, and no query API, with state living inside the Dapr sidecar.
The component is only a few lines. Save it as `./components/statestore.yaml`:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: flockstate
spec:
type: state.in-memory
version: v1
The Flock application loads its configuration through Dapr and passes it to the blackboard store, so nothing is hardcoded in the source.
from flock import Flock, PublicVisibility, flock_type
from flock.storage.dapr import (
DaprStateBlackboardConfig,
DaprStateBlackboardStore,
)
# Load config and secrets from the Dapr secret store.
secrets = load_dapr_secrets("http://localhost:50001")
store_config = DaprStateBlackboardConfig(
store_name=secrets["store_name"],
supports_transactions=secrets["supports_transactions"],
supports_etag=secrets["supports_etag"],
supports_ttl=secrets["supports_ttl"],
supports_dapr_query_lang=secrets["supports_dapr_query_lang"],
encrypted_backend=secrets["encrypted_backend"],
backend_encryption_key=secrets["backend_encryption_key"],
consistency=secrets["consistency"],
)
dapr_store = DaprStateBlackboardStore(config=store_config)
flock = Flock(
model=secrets["default_model"],
store=dapr_store, # Dapr-backed blackboard
)
# ... define artifacts and agents exactly as above ...
await flock.serve(dashboard=True)
Start the app with a Dapr sidecar in a single command:
dapr run --app-id flock-dev --dapr-grpc-port 50001 \
--resources-path ./components -- python app.py
This launches the Dapr sidecar next to your process, loads every component from ./components (the flockstate store you just defined), and then runs app.py. Flock talks to that sidecar over gRPC on port 50001, which is the endpoint the store client connects to.
Dapr now defines what the environment looks like and how it behaves. The application does not really know what kind of backend it is going to get, and it does not have to. All it does is ask Dapr what the store looks like. Flock adapts to the environment it is deployed to, not the other way around. Secrets, by the way, live where they belong: in a Dapr secret store, not the source tree.
PostgreSQL: durable and transactional
The PostgreSQL backend is where the example starts to feel like production. The blackboard state is backed by a durable database, and the component enables transactional writes and ETags with strong consistency. Point a local PostgreSQL instance at Dapr with a one-line container:
docker run -d --name flock-postgres -p 5432:5432 \
-e POSTGRES_PASSWORD=your-password \
-e POSTGRES_DB=flock_dapr postgres:17
This starts a PostgreSQL container in the background, exposed on the standard port 5432, with an empty flock_dapr database ready for Dapr to use. The password and database name here have to match the connection string in the component below.
Then swap the component. Only the spec block changes:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: flockstate
spec:
type: state.postgresql
version: v2
metadata:
- name: connectionString
value: "host=localhost port=5432 user=postgres password=your-password dbname=flock_dapr"
Now the infrastructure is a little more capable. Does the Flock application need to change? Not at all, and this is exactly where Dapr shows its value. The Python is byte-for-byte identical to the in-memory version: the same artifacts, the same agents, the same flock.serve(dashboard=True). Only the component file and a handful of capability flags in the secret store moved, and this time the application got transactions, ETags, and a durable database. You start it with the same dapr run command as before.
Redis encrypted: hardened for cloud-native deployment
The encrypted Redis profile is the most security-oriented one in the set. The state is encrypted at rest through the Flock configuration, which is a strong fit for environments where the blackboard holds real operational data. Run a Redis Stack container, which enables the query API out of the box, with a password:
docker run -d --name flock-redis -p 6379:6379 \
-e REDIS_ARGS="--requirepass your-password" \
redis/redis-stack:latest
This starts a Redis Stack container, which is Redis plus the RediSearch and RedisJSON modules, so the Dapr query API works without any extra setup. The `REDIS_ARGS` value sets a password on the instance, which the component then uses to authenticate.
Then point the component at it:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: flockstate
spec:
type: state.redis
version: v1
metadata:
- name: redisHost
value: localhost:6379
- name: redisPassword
value: "your-password" # in production, reference a Dapr secret store instead
Encryption is turned on through the Flock capability flags the app already reads from its secret store, encrypted_backend and backend_encryption_key. The application code, again, does not change.
There is one important detail to call out clearly. Encrypted backends disable transactions in this integration because of a Dapr runtime serialization limitation. That is not a flaw in the Flock design; it is exactly the kind of infrastructure boundary that Dapr is meant to absorb. The application still gets a resilient, encrypted blackboard, but the integration is honest about what the backend can safely guarantee rather than pretending otherwise.
Why this matters
The real win is not that Flock can talk to Dapr. The real win is that Flock and Dapr share the same philosophy. Flock already treats the blackboard as the center of the system. Dapr gives that blackboard a production-grade runtime boundary. Put together, agents stay declarative, state is externalized, secrets stay out of source control, resilience is handled consistently by infrastructure, and the backend can evolve without rewriting the swarm.
That is the cloud-native story we wanted from the start. It removes friction from future development, keeps the agent implementation focused on domain logic, and lets the underlying state layer become someone else’s problem in the best possible way. If you are building Flock agents and you already think in terms of distributed systems, Dapr is a very natural fit. It gives the blackboard the infrastructure it deserves, while the agents stay small, declarative, and easy to reason about.
Dapr or SQLite? A quick decision guide
Not every project needs a distributed backend, and Flock ships a built-in SQLite-backed persistent blackboard for exactly that reason. Here is how we decide:
| You need | Reach for |
|---|---|
| Single-node durable history, simple local operations | SQLite persistent blackboard |
| Shared state across multiple Flock instances | Dapr state store |
| Pluggable backend infrastructure without code changes | Dapr state store |
| Encryption at rest, TTL, or backend query support | Dapr state store |
The short version: if you are single-process, start with SQLite. The day you need a second instance, encryption at rest, or a backend swap without touching application code, move to Dapr and change nothing in your agents. The full comparison lives in the guide under choosing SQLite vs Dapr.
Building production agent systems?
If you are taking agent workflows toward production and want the operational layer to hold up under real load, schedule a call to talk about how Flock could help your agents. We build cloud-native, agentic systems on this kind of foundation every day.
Further reading