Der größte Kostenhebel bei AI Engineering ist nicht das Modell, es ist die Disziplin
Seit Monaten dreht sich die Diskussion um AI-Coding-Tools fast ausschließlich um eine Frage: Welches Modell ist das beste? Claude Opus oder Sonnet? GPT-5.4 oder GPT-5.3-Codex? Haiku für einfache Aufgaben? Das ist die falsche Frage.
Das richtige Modell zu wählen ist ein Hebel. Aber es ist nicht der Hebel. Wer agentische Sessions wie Chats führt, kann sich durch Modellwahl nicht aus dem Problem optimieren – egal wie günstig Haiku ist. Der eigentliche Kostenhebel ist Disziplin: wie man Aufgaben spezifiziert, wie man Context kontrolliert, und wie man Sessions führt.
Dieser Post erklärt, warum – und was man konkret tun kann.
Inhalt
- Warum das gerade jetzt relevant wird
- Warum Agent-Sessions strukturell anders sind
- Drei Disziplinen, die den Unterschied machen
- Modellwahl: Ein Hebel, nicht der Hebel
- Tools: Was Sie schon haben – und drei die Sie einsetzen sollten
- GitHub Spec Kit
- RTK und Caveman Mode: Zwei Seiten desselben Problems
- Der nächste Schritt: Orchestrierte Agent-Pipelines
- Was danach kommt: Strukturierte Multi-Agent-Pipelines
- Fazit: Die These hält
Warum das gerade jetzt relevant wird
Der Markt kippt. Innerhalb weniger Monate hat fast jeder relevante Anbieter auf Token-basierte Abrechnung umgestellt oder kündigt es an. GitHub Copilot wechselt zum 1. Juni 2026 von Request-basierter auf Token-basierte Abrechnung. Claude Code ist bereits dort. OpenAI und Cursor – gleiches Bild.
Das ist kein Zufall. Es ist die logische Konsequenz der Adoption-Kurve: 84% der Entwickler nutzen AI-Tools, 41% des Codes ist bereits AI-assistiert, 90% der Fortune-100-Unternehmen zahlen für AI-Coding-Tools. Bei dieser Nutzung können Anbieter keine Flatrate-Subventionen mehr aufrechterhalten.
Was das praktisch heißt: GitHub schreibt in der Ankündigung des neuen Abrechnungsmodells, es sei „common for a handful of requests to incur costs that exceed the plan price”. Das ist kein Ausnahmefall für Heavy User – das ist die neue Normalität für jeden, der Agents ernsthaft einsetzt.
Die gute Nachricht: Aus unserer Projekterfahrung entstehen ein erheblicher Teil dieser Kosten durch vermeidbare Patterns. Nicht durch die Aufgabe, sondern durch die Art wie man arbeitet.
Warum Agent-Sessions strukturell anders sind
Hier liegt der Kern des Problems – und er ist den meisten Entwicklern nicht intuitiv klar.
Das mentale Modell der meisten Entwickler ist von ChatGPT geprägt: ein offener Tab, stundenlang offen, Frage rein, Antwort raus, neue Frage. Lange Sessions sind harmlos. Kosten sind linear. Agentische Sessions funktionieren anders. Im Chat-Modell ist jede Antwort unabhängig. Eine Frage kostet einen festen Betrag, die nächste genauso viel. Der Verbrauch ist linear und vorhersehbar.
Im Agent-Modell liest jeder Turn die gesamte bisherige History als Input neu. Der Agent erinnert sich nicht – er liest den gesamten Verlauf neu. Das hat konkrete Folgen:
- Turn 1 – Spec und Plan lesen: rund 5.000 Tokens
- Turn 2 – History von Turn 1 plus neue Datei: rund 15.000 Tokens
- Turn 5 – vier Turns History plus Tool-Output: rund 60.000 Tokens
- Turn 10 – gesamte bisherige History plus neue Tools: rund 150.000 Tokens
- Turn 30 – alles davon plus eine neue Datei: über 400.000 Tokens
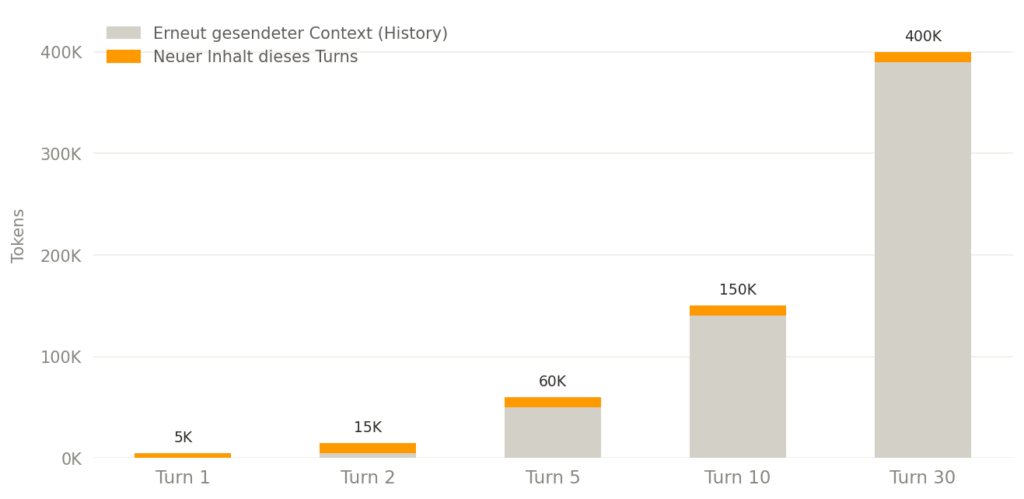
Was dabei in den Context wandert, ohne dass man es aktiv entscheidet: der System-Prompt, AGENTS.md, alle MCP-Tool-Schemas, jeder gelesene File-Inhalt, jede Terminal-Ausgabe (npm test mit 200 Tests produziert tausende Zeilen), jeder Git-Diff, jeder Tool-Output. Allein fünf angebundene MCP-Server können laut Anthropic bis zu 18.000 Token Overhead erzeugen – pro Turn, auch wenn kein einziges Tool aufgerufen wird.
Was das konkret kostet: Anthropic veröffentlicht in den Claude Code Cost Docs reale Enterprise-Durchschnittswerte: Rund 13 Dollar pro Entwickler pro aktivem Tag, 150 bis 250 Dollar pro Monat. Ein GitHub Copilot Business Seat kostet 19 Dollar pro Monat – und enthält 19 Dollar in AI Credits. Bei 13 Dollar pro aktivem Tag reicht dieses Budget für anderthalb Arbeitstage. Den Rest des Monats zahlt man on top. Mit Disziplin – kürzere Sessions, sauberere Specs, kontrollierterer Context – sinkt dieser Tageswert drastisch, und das Inklusiv-Budget reicht tatsächlich für einen Monat.
Der Unterschied ist nicht das Modell. Es ist, wie man arbeitet.
Drei Disziplinen, die den Unterschied machen
Die drei Disziplinen sind keine unabhängigen Tipps – sie greifen ineinander. Spec-Driven Development reduziert, was überhaupt in eine Session geht. Context Engineering reduziert, was pro Turn in den Context geladen wird. Session-Disziplin begrenzt, wie lange eine Session läuft, bevor der Context exponentiell teuer wird. Zusammen adressieren sie alle drei Phasen desselben Problems.
1. Spec-Driven Development: Erst denken, dann coden lassen
Das Gegenteil von Spec-Driven Development heißt Vibe Coding: einen Agent auf ein vage definiertes Ziel loszuschicken – ohne Anforderungen, ohne Constraints, ohne klare Erfolgskriterien.
Vibe Coding funktioniert für Wegwerf-Prototypen. Für Production-Code ist es teuer. Ohne präzise Spec exploriert der Agent: er scannt das Repository nach Orientierung, trifft eigene Annahmen über Framework-Wahl, Datenmodell und Error-Handling, iteriert mehrfach in die falsche Richtung und erzeugt dabei deutlich mehr Token-Verbrauch als eine gezielte Implementation. Das Ergebnis läuft vielleicht – aber es verletzt nicht ausgesprochene Anforderungen oder trifft Architekturentscheidungen, die nie abgesegnet wurden.
Spec-Driven Development verwandelt Spezifikationen von passiver Dokumentation in ausführbare Contracts. Eine gute Spec hat sechs Elemente:
- Outcomes – Was der gewünschte Zustand ist, nicht wie er erreicht wird
- Scope Boundaries – Was explizit nicht in Scope ist
- Constraints – Tech-Stack, Architektur-Regeln, Limits
- Prior Decisions – Was bereits entschieden ist und nicht zur Diskussion steht
- Task Breakdown – Sequenzierte, abhängigkeitsgeordnete Schritte
- Verification Criteria – Messbare, prüfbare Akzeptanzkriterien
Der eigentliche Token-Spareffekt kommt aus dem Workflow, der daraus folgt: Der Workflow trennt zwei Schritte, die die meisten Teams vermischen: Denken und Umsetzen.
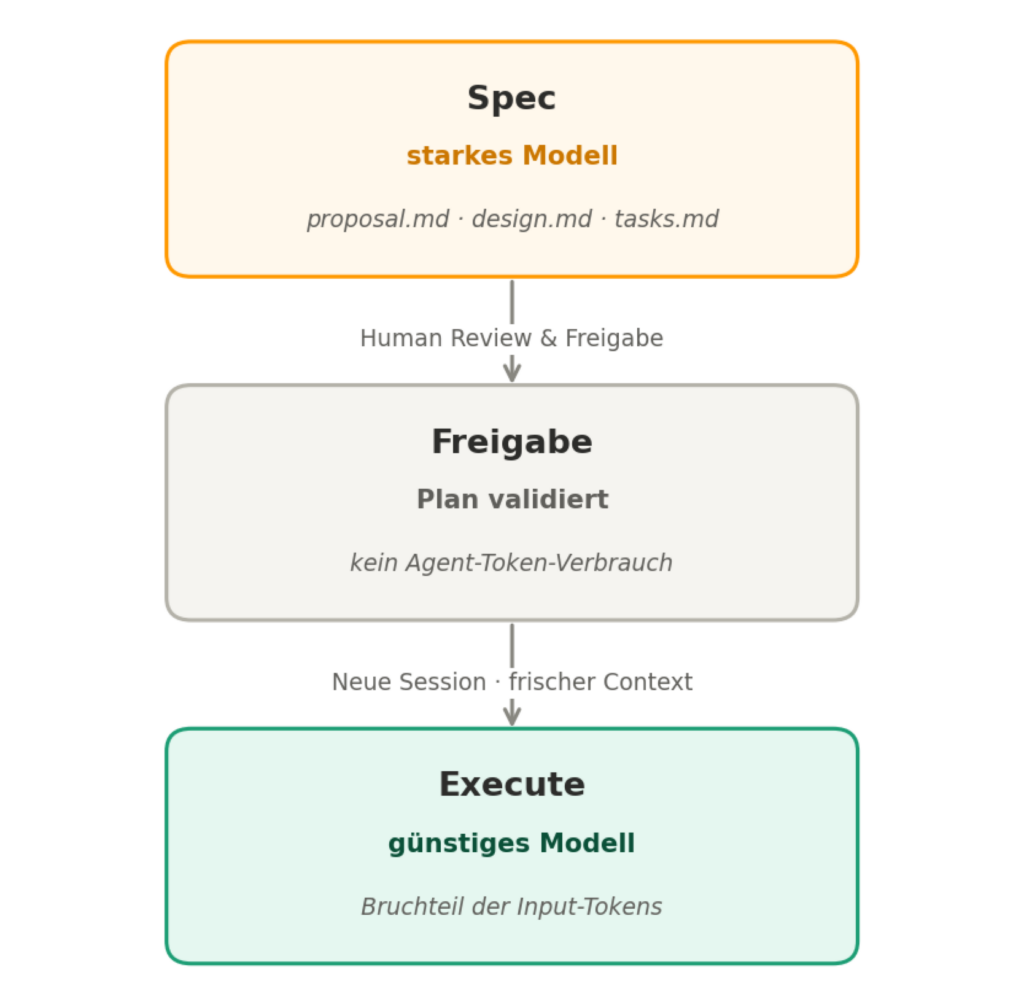
Zuerst entsteht die Spec – und das mit einem leistungsstarken Modell. Der Aufwand lohnt sich: Ein starkes Modell produziert einen Plan mit echtem Tiefgang, der Abhängigkeiten erkennt, Scope-Fallen benennt und die Implementierungsschritte so klar formuliert, dass wenig Interpretationsspielraum bleibt. Das Ergebnis sind drei Dokumente: proposal.md für Was, Warum und Scope, design.md für das technische Design mit betroffenen Dateien und APIs sowie tasks.md als sequenzierter Implementierungsplan mit prüfbaren Akzeptanzkriterien. Dann folgt Human Review – ein Mensch prüft den Plan und gibt ihn frei.
Erst danach beginnt die Implementierung. Und das mit einem günstigeren Modell in einem frischen Agent mit frischem Context. Der entscheidende Effekt: Ein präzise ausgearbeiteter Scope lässt sich von einem leichteren Modell in hoher Qualität ausführen. Der Agent muss nicht explorieren, nicht raten, nicht iterieren. Er arbeitet einen klaren Plan ab. Die gesamte Explorations-History der Planungsphase wird weggeworfen – was bleibt, sind die Ergebnisse. Damit startet die Implementierung mit einem Bruchteil der Input-Tokens, die ein direkt gestarteter Agent-Run ohne vorherige Spec verbraucht hätte.
2. Context Engineering: Das Richtige rein, nicht alles
„Context ist King” ist ein verbreiteter Ratschlag. Er ist halb richtig. Zu wenig Context und der Agent trifft falsche Annahmen. Zu viel Context erzeugt Rauschen, das die Reasoning-Qualität senkt und dabei jeden Turn teurer macht. Der präzise Satz lautet: Der richtige Context ist King.
Die zentrale Struktur ist eine Hierarchie:
Immer geladen – AGENTS.md: Einmalinvestition pro Repository. Enthält Projektstruktur (verhindert Discovery-Loops durch das ganze Repo), Build- und Test-Commands und Konventionen, die vom Standard abweichen. Wird gecacht – Cache-Hits kosten beim erneuten Lesen nur 10 Prozent des normalen Input-Preises.
Was nicht in AGENTS.md gehört: allgemeine Projektdokumentation, Feature-Beschreibungen, alles was sich öfter als monatlich ändert. Das Prüfkriterium für jede Zeile: Weicht diese Regel vom Default-Verhalten ab, und ist sie für mehr als 30 Prozent der täglichen Tasks relevant? Wenn nein – raus, oder in einen Skill.
Bei Bedarf geladen – Skills und Prompt Files: GitHub Copilot unterscheidet zwischen zwei Mechanismen für on-demand Context:
- Skills sind Markdown-Dateien mit schwerer, wiederverwendbarer Guidance – der Agent scannt beim Session-Start nur das Verzeichnis, weiß welche Skills existieren, und lädt den vollständigen Inhalt inklusive MCP-Tool-Definitionen erst wenn er ihn aktiv braucht.
- Prompt Files (
.github/prompts/*.md) sind der zweite Mechanismus: vordefinierte Workflows für repetitive Aufgaben wie „create a unit test” oder „write a PR description”, die explizit aufgerufen werden.
Beides trennt, was immer geladen wird von dem was nur bei Bedarf in den Context kommt. Es geht noch granularer: Custom Instructions lassen sich mit applyTo-Globs auf bestimmte Dateimuster einschränken: applyTo: "**/*.test.ts". Das bedeutet: Testing-Konventionen landen nur im Kontext, wenn Testdateien bearbeitet werden. Das eliminiert das häufigste Anti-Pattern: alle MCP-Tool-Schemas von Beginn an laden, auch wenn die Mehrheit nie aufgerufen wird.
VS Code Erweiterungen und offene Tabs prüfen: Zwei oft übersehene Context-Aufbläher: installierte VS Code Erweiterungen und geöffnete Tabs. Viele Erweiterungen injizieren automatisch Instruktionen, Workspace-Informationen oder Tool-Definitionen in den Agent-Context – ohne aktive Konfiguration. Gleichzeitig landen alle geöffneten Dateien bei jedem Copilot-Request im Context, unabhängig davon ob sie für die aktuelle Aufgabe relevant sind. Es lohnt sich beides zu prüfen: Erweiterungen deaktivieren die keinen Beitrag leisten, und nicht benötigte Tabs schließen. Besonders in Enterprise-Umgebungen mit standardisierten Workstations summiert sich das schnell.
Session-spezifisch: Explizit referenzierte Dateien (@datei.ts statt #codebase), die aktuelle Spec, konkrete Fehlerausgaben. Direkte Referenzierung statt Repository-Discovery vermeidet, dass der Agent die halbe Codebase scannt, um den Einstiegspunkt zu finden.
3. Session-Disziplin: Das Anti-Chat-Verhalten
Die dritte Disziplin ist die einfachste zu verstehen – und die schwerste gegen die eigene Gewohnheit durchzusetzen.
Eine Session = eine abgegrenzte Aufgabe. Kein offener Tab für den ganzen Tag. Kein „lass mal den Agent auch noch das prüfen”. Bei Themenwechsel: /clear. Wenn der Agent in einer Sackgasse steckt: stoppen, Roll-back auf den letzten sauberen Commit, präzisere Spec – nicht „fix das mal” als nächsten Turn.
Proaktives Compacting: /compact aktiv am Ende eines Subtasks nutzen, nicht auf das automatische Compacting bei 95 Prozent Context-Füllstand warten. Wichtig: die produzierte Zusammenfassung prüfen. Kritische Architektur-Entscheidungen und Konventionen gehören in AGENTS.md – nicht in den Verlauf, der beim Compacting verloren geht.
Sub-Agents für parallele Workstreams: Statt einem großen Agent für ein ganzes Feature übernehmen spezialisierte Agents mit eigenem, frischem Context:
- Ein Frontend-Agent arbeitet ausschließlich im UI-Bereich und kennt nur die relevanten UI-Tools
- Ein Backend-Agent ist auf die API- und Service-Schicht beschränkt, ohne Zugriff auf Infrastruktur
- Ein Infra-Agent bewegt sich nur in den Terraform-Modulen und Cloud-Ressourcen
Ein Orchestrator koordiniert die Ergebnisse – bekommt aber nur kompakte Zusammenfassungen, nicht die vollständige Chat-History jedes einzelnen Agents.
Explizite Bounds setzen: Agentische Loops iterieren bis das Ziel erreicht ist – oder bis das Token-Budget aufgebraucht ist. Explizite Stop-Bedingungen verhindern das: max_attempts: 2 in der Agent-Konfiguration, oder eine klare Instruktion im Prompt wie „stoppe nach dem ersten grünen Testlauf”. Ohne diese Bounds kann ein einzelner Agentic-Run unkontrolliert eskalieren.
Steering-Disziplin: Beaufsichtigte Sessions erlauben frühe Korrekturen – bevor ein Fehlverständnis 20 teure Turns tief geht. Overnight-Runs sind kein Zeitsparer per se, sondern ein bewusster Trade-off. Ohne sehr gute Spec und explizite Bounds kann ein Overnight-Run mehr Tokens verbrennen und mehr Rework produzieren als eine beaufsichtigte 2-Stunden-Session.
Modellwahl: Ein Hebel, nicht der Hebel
Modellwahl ist real relevant – aber sie repariert keine schlechte Disziplin. Eine 30-Turn-Endlos-Session mit Haiku ist nicht günstig, sie ist nur langsam teuer.
Die Drei-Tier-Logik hat trotzdem ihren Platz:
| Tier | Geeignet für | Nicht geeignet für |
|---|---|---|
| Leichtgewicht | Zusammenfassen, Formatieren, Rename, einfache Tests, Boilerplate | Komplexe Implementierung, Architektur |
| Standard | Feature-Entwicklung, Bug-Fixes, Refactoring, Planung | Tiefes Reasoning, schwere Entscheidungen |
| Powerhouse | Architektur-Decisions, Plan-Reviews, schwere Bugs, komplexe Specs | Einfache, repetitive Tasks |
Bei unterstützten Modellen kommt eine zweite Dimension hinzu: Das Reasoning-Level (low / medium / high). Viele aktuelle Modelle lassen sich in ihrer Denktiefe explizit steuern. High Reasoning verbraucht deutlich mehr interne Tokens – bei einfachen Tasks reine Verschwendung, bei komplexen Architektur-Entscheidungen oder schweren Debugging-Szenarien kann es Turns und Rework einsparen. Die Faustregel: Reasoning-Level wie Modell-Tier behandeln – zum Task kalibrieren, nicht auf Maximum belassen.
Eine wichtige Nuance: Token-Preis ist nicht gleich Aufgabenkosten. Ein stärkeres Modell kann bei komplexen Aufgaben insgesamt günstiger sein, weil es weniger Turns braucht um das Ziel zu treffen. Ein günstigeres Modell das dreimal iteriert und Rework produziert, kostet unter Umständen mehr als ein teureres das einmal präzise liefert. Deshalb empfehlen wir für die Spec-Phase bewusst ein leistungsstarkes Modell – nicht trotz der höheren Token-Kosten, sondern wegen der höheren Effizienz im Ergebnis. Bei einfachen, klar definierten Tasks gilt das Gegenteil: dort bringt ein stärkeres Modell keine bessere Qualität, nur höhere Kosten. Der Maßstab ist nicht der Preis pro Token – es ist der Preis pro abgeschlossenem Task.
Für Organisationen empfiehlt sich Auto Model Selection als Default-Einstellung: GitHub wählt dabei automatisch das für die jeweilige Aufgabe angemessene Modell – einfache Completions landen bei leichteren Modellen, komplexe Reasoning-Tasks werden entsprechend eskaliert. Das nimmt Entwicklerinnen und Entwicklern die Entscheidung im Tagesgeschäft ab, ohne die Möglichkeit zum manuellen Override zu nehmen.
Eine spezifische Warnung für Annual-Plan-Subscriber: Wer zum 1. Juni auf dem alten Annual-Plan bleibt, bekommt neue Modell-Multiplier. Claude Sonnet 4.6 springt von Multiplier 1 auf 9. Opus 4.6 von 3 auf 27. Das ist jeweils ein 9-facher Anstieg für die gleiche Nutzung. Wer aktiv mit Premium-Modellen arbeitet, sollte vor dem 1. Juni in einen Monthly Usage-Based Plan wechseln – anteilige Credits werden gutgeschrieben. Die aktuellen Multiplier und Preise finden sich direkt in der GitHub Copilot Models & Pricing Dokumentation.
Aber die These bleibt: Modellwahl ohne die drei Disziplinen löst das Problem nicht. Sie verlangsamt es nur.
Tools: Was Sie schon haben – und drei die Sie einsetzen sollten
Sichtbarkeit schaffen: /usage und /context in Copilot CLI zeigen Token-Verbrauch und Context-Füllstand jederzeit. Preview Bill ist seit Anfang Mai 2026 im Billing Overview verfügbar – Pflicht, um die eigene Baseline vor dem Umstieg zu verstehen.
Workflow-Mechaniken: Plan Mode (Shift+Tab in Copilot CLI) ist offiziell von GitHub für Token-Effizienz empfohlen: strukturierter Plan vor der Implementation, deutlich weniger explorative Loops. /compact für proaktive Context-Komprimierung. @datei.ts statt #codebase für direkte Dateireferenzierung.
Konfiguration (Enterprise/Business Admins): MCP-Toolsets scopen – nur was das Projekt braucht. Content Exclusion für Build-Output, generierte Dateien, Logs. Einschränkung: Content Exclusion wirkt nicht für CLI, Cloud Agent und Agent Mode – nur für Inline und Chat.
GitHub Spec Kit
GitHub stellt mit dem Spec Kit ein Open-Source-Toolkit bereit, das den SDD-Workflow direkt im Editor abbildet. Die drei Slash Commands /specify, /plan und /tasks führen strukturiert durch die Planungsphasen und produzieren automatisch proposal.md, design.md und tasks.md – ohne manuellen Aufwand außerhalb des Editors.
Spec Kit bringt zusätzlich constitution.md in den Workflow ein: ein Dokument für nicht-verhandelbare Projektprinzipien wie Security-Rules, Testing-Anforderungen und Architektur-Constraints, die unabhängig von jedem einzelnen Feature Vorrang haben. Die entstehenden Spec-Dateien werden ins Repository committed und versioniert. Sie sind damit das persistente Onboarding-Dokument für jeden Agent, der auf dem Repo arbeitet – heute und in sechs Monaten.
RTK und Caveman Mode: Zwei Seiten desselben Problems
| Tool | Problem das es löst | Wirkung |
|---|---|---|
| GitHub Spec Kit | Fehlende Struktur vor Agent-Runs | SDD-Workflow direkt im Editor |
| RTK | Terminal-Output bläht Context auf | Bis zu 90% weniger Output von Test-Runs |
| Caveman Mode | Agent produziert verbose Reasoning-Output | Bis zu 75% weniger Output-Tokens in Loops |
RTK – Rust Token Killer setzt am Terminal-Output an. Wer jemals einen Agent-Run mit aktivem Testlauf beobachtet hat, kennt das Problem: der vollständige Output von npm test – jede erfolgreiche Zeile, jede Laufzeitangabe, jede Zusammenfassung – landet komplett im Context des nächsten Turns. RTK hängt sich als Pre-Hook vor CLI-Commands und verdichtet diesen Output, bevor er den Agent erreicht. Für den Agent ist die Kompression vollständig transparent – er sieht das relevante Ergebnis, nicht die Rohausgabe. In einer typischen 30-Minuten-Session reduziert RTK den Context-Verbrauch von Test-Runs um bis zu 90 Prozent, von Git-Diffs um etwa 75 Prozent – über eine Session gerechnet 60 bis 90 Prozent weniger Terminal-Output-Tokens. RTK lässt sich über Homebrew mit einem Befehl installieren und für GitHub Copilot einrichten.
Caveman Mode setzt am Output des Agents selbst an. Agentische Reasoning-Loops produzieren von Haus aus ausführliche Sprache: Einleitungen, Erklärungen, Absicherungen, bevor die eigentliche Antwort kommt. Statt „Ich freue mich, Ihnen helfen zu können. Der Fehler, den Sie beschreiben, liegt vermutlich in der Authentication Middleware, genauer gesagt…” produziert der Agent mit Caveman: „Bug auth middleware. Token expiry. Fix.” Das macht bis zu 75 Prozent Output-Token-Einsparung in Agent-internen Loops möglich – ohne Qualitätsverlust bei der eigentlichen Implementation. Wer Caveman nicht installieren möchte, erreicht denselben Effekt über Custom Instructions: „Keine Einleitungen. Antworten prägnant. Details nur auf explizite Nachfrage.”
Der nächste Schritt: Orchestrierte Agent-Pipelines
Bevor wir über vollständig autonome Pipelines sprechen, lohnt ein Blick auf etwas das heute schon verfügbar ist: den GitHub Copilot Cloud Agent.
Der Cloud Agent bekommt ein Issue als Input und arbeitet autonom – ohne Tab-Wechsel, ohne Steering, ohne menschliche Korrekturen in der Mitte. Genau das macht ihn zum direkten Test-Case für die drei Disziplinen.
Das Issue ist die Spec. Ein vages Issue mit drei Bullet Points produziert einen explorativen Agent, der das Repository scannt, Annahmen trifft und teure Turns verbrennt. Ein präzises Issue mit Akzeptanzkriterien, Dateireferenzen und explizitem Out-of-Scope produziert eine gezielte Implementation. AGENTS.md ist der gesamte Context, den der Cloud Agent kennt – ohne diese Datei produziert er Code, der nicht zum Projekt passt. Und weil es kein Steering gibt, ist Session-Hygiene keine Option mehr, sondern Voraussetzung.
Der Cloud Agent ist damit der Lackmus-Test: Wer Software Design Description (SDD), Context Engineering und Session-Disziplin beherrscht, kann ihn produktiv und kosteneffizient nutzen. Wer nicht, sieht denselben Burn wie bei einer entgleisten lokalen Session – nur ohne die Möglichkeit einzugreifen.
Was danach kommt: Strukturierte Multi-Agent-Pipelines
Mehrere Cloud-Agent-Runs, orchestriert auf klar abgegrenzten Sub-Issues, mit automatisierten PR-Reviews zwischen den Schritten – das ist der nächste Reifegrad. Heute baubar mit vorhandenen Bordmitteln.
Die Frage verschiebt sich dann von „guter Prompt” zu „gutes System-Design”: Ein Planungs-Agent definiert den Ansatz, ein Implementierungs-Agent setzt um, ein Evaluierungs-Agent prüft gegen die Spec, ein manuelles Review-Gate öffnet nur bei auffälligen Ergebnissen. Stripe produziert nach Berichten mehr als 1.300 AI-generierte PRs pro Woche nach diesem Prinzip – nicht durch einen freien Agent, sondern durch mehrere spezialisierte in einem strukturierten Workflow.
Vollständig autonomes Shipping – ohne Human Review in der Schleife – existiert bereits in kontrollierten Kontexten. Es setzt sehr hohe Testabdeckung als Proxy für manuelles Review, engen Task-Scope und vollständige Observability voraus. Das ist kein Freifahrtschein für Agents, sondern das Gegenteil: maximale Struktur als Voraussetzung für maximale Autonomie.
Der gemeinsame Nenner aller dieser Ausbaustufen: Je höher die Autonomie, desto kritischer wird die initiale Spec-Qualität. Wer Vibe Coding nicht aufgibt, wird strukturierte Agent-Pipelines nicht produktiv betreiben können – nicht weil die Tools fehlen, sondern weil das Fundament fehlt.
Fazit: Die These hält
Zurück zur Ausgangsfrage: Welches Modell ist das beste?
Die ehrliche Antwort: Es kommt fast nicht darauf an, solange die drei Disziplinen nicht sitzen. Haiku in einer offenen 30-Turn-Session ohne Spec ist nicht günstig. Opus in einer sauberen 5-Turn-Session mit präziser Spec ist nicht teuer.
Der größte Kostenhebel bei AI Engineering ist nicht das Modell. Es ist die Disziplin.
Drei Maßnahmen, die sich sofort umsetzen lassen:
- Spec-Driven Development einführen. GitHub Spec Kit installieren,
/specifyvor dem nächsten Feature ausführen. Einen Turn in Planung investieren spart zehn Turns in Exploration. - AGENTS.md pro Repository anlegen. Einmalinvestition. Projektstruktur, Commands, kritische Konventionen. Wird gecached, zahlt sich bei jeder Session aus.
- RTK für GitHub Copilot eingerichtet und bis zu 80 Prozent Terminal-Output-Einsparung, transparent für den Workflow.
Das sind keine Hacks. Es sind die Grundlagen für die Art von AI-gestützter Entwicklung, die auch in sechs Monaten noch funktioniert – unabhängig davon, wie sich Preismodelle weiterentwickeln. Token-basierte Abrechnung ist nicht der letzte Schritt dieser Entwicklung.